Amazon Data Extraction Engine
Crawl, Scrape and Parse Amazon Content
System requirements: dedicated server + rotating proxies
Product Description
Mass Data Extraction
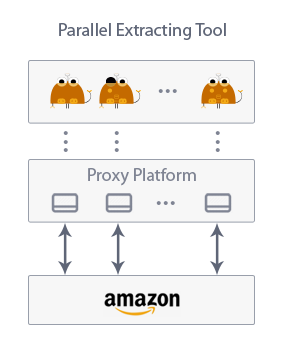
The Data Extraction Engine is designed for the high performance of mass data extraction. Parallelized algorithms allows to run multiple simulations through a proxy-rotating platform.
On a dedicated server + rotating proxy account it is capable to sync hundreds of thousands of Amazon products every day.
Rich Configuration Instructions
It is easy to configure the Engine for certain needs. For example, you can scrape by a seller or prime status and exclude international merchants. You can exclude products like Add-ons, which are not sold alone or sold with additional fees.
Rich configuration instructions allow to build a proper workflow, and it will make accommodate HTML structure changes quite fast.
Custom Data Flow
Each package is tailored to your needs.
The advanced dataflow contains a set of opportunities for status tracking, importing, cleaning and preparing data for analysis so it can be easily and properly queried and analyzed in the analytics tools.
This makes it possible to manipulate your data and perform advanced calculations using data mining and machine learning algorithms.
Private Deployment
Our platform deploys quickly and scales easily. Integrate Data Extraction platform with your enterprise systems, while satisfying stringent data security and privacy. We offer flexible Private Deployments that can run in private cloud or on-premise. We can give your developers the utmost flexibility in automating sophisticated data flows end-to-end via API plus rich XML configuration.
The private deployment, and rich toolset help users create, rapidly experiment, fully automate, and manage data workflows to power intelligent applications.
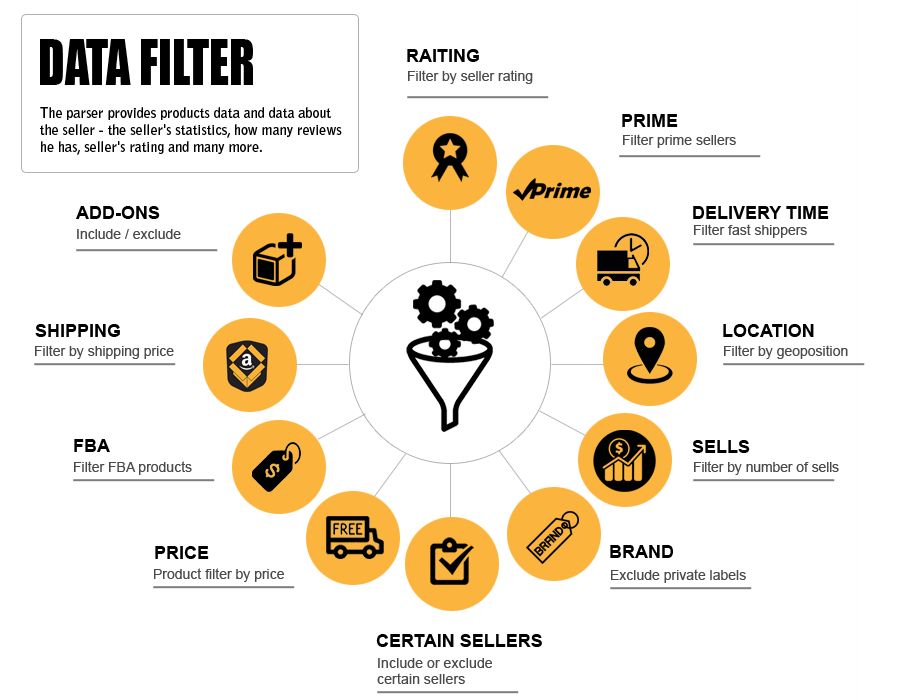
What Amazon’s Data You Can Extract
- Prime offers
It is possible to get prime offers, i.e. Parser will take the prime offer with the lowest price. - Seller rating
It is one of the most important factors displayed on the product page. Seller rating is measured the customer experience seller provide. - Seller feedback
The reviews buyers leave of seller service and products. It’s displayed in the customer feedback section. - Delivery time
You can filter the fastest shippers - Seller location
You can filter sellers by geoposition. For example, exclude China sellers. - Sells number
You can filter sellers by number of sells. For example, include only sellers with more than 500 sells. - Brand
You can exclude private labels or filter by it. - Certain sellers
You can set the system to scrape by certain sellers and get most of the data from it. You can define certain seller for all products or ban some sellers - FBA products
It is possible to filter FBA products. - Shipping price
The shipping price is location specific. - ADD-ons
It is possible to exclude add-ons which are not sold alone or sold with additional fees. - Quantity, price, description, images, title, reviews
Offers page and product page are scraped. - Price changes
In the database, there is a DateTime of the last price/qty change. - Shipping weight
By default shipping weight is placed to database. Or just weight. Some products do not have that value. - Add-on items
It is possible to see if the product is Add-on - EAN, MPN, UPC
In most cases, EAN, MPN, UPC are not available on the HTML.
The demo is set up to extract the following data:
- product_id
- parent_asin
- price
- prime
- sku
- locale
- offer(url) / offers_data
- merchantOffer(url)
- merchantId / merchantName
- product(url)
- title
- stock / StockString
- isAddon
- category
- description
- short_description
- images(url)
- mpn / ean / upc
- brand / made_by / manufacturer
- model
- dimension / dimension_data
- weight
- delivery / delivery_data
- variation_attributes
- sync_speed / curl_code / sync_flag / sync_log
- created / modified / updated_date
- next_update_date
- marketplace_category
- marketplace_category_name
- web_hierarchy_location_codes / web_hierarchy_location_name

Update Price and Stock as Fast as You Need
How many Amazon products can the system scrap per hour? The software is designed to update price/stock as fast as you need. The speed is totally a matter of server resources. For example, 500k products are well-updated on a regular $100/mo dedicated server.
Deploying and Running The Data Extraction Engine
Dedicated server + rotating proxies
Since the system is deployed on your personal servers, it provides privacy and compliance. You control what data parsing and saving occurs across your server.
It might be enough to have a $40/mo proxies account for 500k ASINs and $100-200/mo proxy account for 1 mln products. Please check Stormproxies.
What server size do you need? Depends on your requirements, for example, if there are 100k products which have to be synced every day, you may need a 4gb ram and 2 CPU machine.
From an overall IT management standpoint, you would have a parsing tool, built-in API, and all you need on the same platform. This is a complete, integrated solution designed for small businesses.
What included in the $590 price?
The price of $590 is without installation and without setup. This means you will have to install and set up the system on your own.
Installation involves: copy files, import database, setup proxies, and make sure everything works.
Since the software is not simple, we strongly recommend purchasing the installation service.